
Data Value Stream.
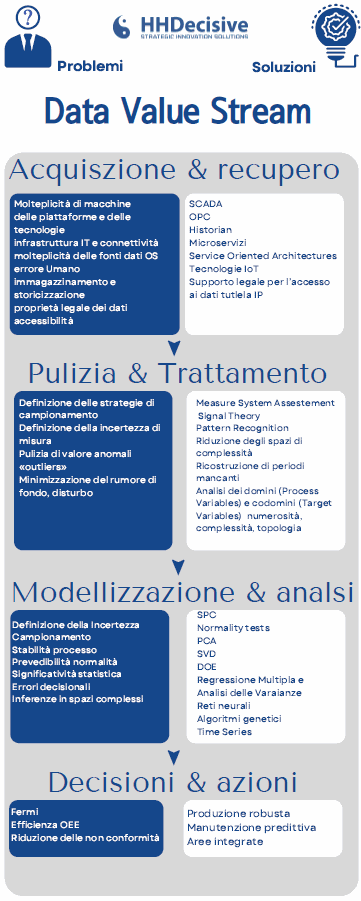
Il nostro processo di Data Value Stream è suddiviso in quattro passaggi fondamentali: l’acquisizione e recupero dei dati, la pulizia e il trattamento di essi, la loro modelizzazione e analisi, seguita dalla fase finale di azioni e decisioni.
 L’obbiettivo della
prima fase, detta
data retrieval
,
è quello di recuperare i dati da macchine di produzione o da scanner 3D e
strumenti di misurazione durante la fase di sviluppo del prodotto. Il recupero
del dato, dalla fonte interessata, è soggetto a diverse sfide, tra le quali il
superamento della barriera legale che i produttori dei macchinari spesso
tengono ad erigere. I fornitori dei macchinari possono evitare l’accesso
diretto ai dati dei propri strumenti attraverso l’utilizzo di sistemi
proprietari, licenze specifiche per i propri software o addirittura una
piombatura della macchina stessa. Non è poi da escludere la possibile barriera
fisica che si pone tra noi e il dato. Il macchinario, infatti, potrebbe non
essere connesso ad una rete e, nel caso lo fosse, bisogna adoperarsi per
instaurare una connessione con esso, studiando la scheda di rete e il sistema
che la gestisce. I dati, gestiti e controllati solitamente da PLC
(Controllore logico
programmabile)
, devono
essere estratti passando per infrastrutture intermedie definite SCADA (
Supervisory Control and Data Acquisition)
. Tramite
l’OPC
(Open Platform Communications)
, una piattaforma laogica superiore, è permesso, invece, l’accesso ai dati di ogni singola macchina. Ma anche gli OPC possono essere collegati tra di loro tramite il MES
(Manufacturing Execution System) che permette di monitorare in maniera completa le risorse
produttive e lo stato di avanzamento degli ordini di produzione.
. Tuttavia poter sfruttare questa varietà di sistemi logici di
organizzazione e archiviazione dei dati costringe solitamente le aziende ad implementare
un progetto su larga scala seguendo un approccio
roll-out
di tipo “Big Ben”, senza alcuna sicurezza sui
risultati. In quest’ottica abbiamo realizzato una serie di servizi dedicati a
favorire l’accesso ai dati abbattendo le barriere fisiche, logiche, legali per
permettere il recupero dei dati in tempo reale anche da una singola macchina, su
cui avviare un progetto pilota.
L’obbiettivo della
prima fase, detta
data retrieval
,
è quello di recuperare i dati da macchine di produzione o da scanner 3D e
strumenti di misurazione durante la fase di sviluppo del prodotto. Il recupero
del dato, dalla fonte interessata, è soggetto a diverse sfide, tra le quali il
superamento della barriera legale che i produttori dei macchinari spesso
tengono ad erigere. I fornitori dei macchinari possono evitare l’accesso
diretto ai dati dei propri strumenti attraverso l’utilizzo di sistemi
proprietari, licenze specifiche per i propri software o addirittura una
piombatura della macchina stessa. Non è poi da escludere la possibile barriera
fisica che si pone tra noi e il dato. Il macchinario, infatti, potrebbe non
essere connesso ad una rete e, nel caso lo fosse, bisogna adoperarsi per
instaurare una connessione con esso, studiando la scheda di rete e il sistema
che la gestisce. I dati, gestiti e controllati solitamente da PLC
(Controllore logico
programmabile)
, devono
essere estratti passando per infrastrutture intermedie definite SCADA (
Supervisory Control and Data Acquisition)
. Tramite
l’OPC
(Open Platform Communications)
, una piattaforma laogica superiore, è permesso, invece, l’accesso ai dati di ogni singola macchina. Ma anche gli OPC possono essere collegati tra di loro tramite il MES
(Manufacturing Execution System) che permette di monitorare in maniera completa le risorse
produttive e lo stato di avanzamento degli ordini di produzione.
. Tuttavia poter sfruttare questa varietà di sistemi logici di
organizzazione e archiviazione dei dati costringe solitamente le aziende ad implementare
un progetto su larga scala seguendo un approccio
roll-out
di tipo “Big Ben”, senza alcuna sicurezza sui
risultati. In quest’ottica abbiamo realizzato una serie di servizi dedicati a
favorire l’accesso ai dati abbattendo le barriere fisiche, logiche, legali per
permettere il recupero dei dati in tempo reale anche da una singola macchina, su
cui avviare un progetto pilota.
Da considerare è, poi, la problematica dello storage del dato, che può variare da diversi gigabyte a numerosi terabyte. Una soluzione consiste nella caratterizzazione dei dati attraverso oggetti matematici che ne facilitano la gestione. Sfruttando le derivate e gli integrali delle curve, il numero di oscillazioni, per esempio, si ottengono delle caratterizzazioni che ben riassumono il funzionamento di macchina. È necessario sin da questa fase, però, ragionare sulle dimensioni del campionamento del dato, la frequenza, le variabili d’ingresso e di uscita, arrivando a definire una mappatura che ci permetta di capire quali dati sono disponibili e quali controllabili.
La seconda fase del processo ha lo scopo di pulire e trattare i dati “ data cleaning” . Il dato che riusciamo ad ottenere dai macchinari, infatti, può arrivare sporco, ovvero con la presenza di valori anomali detti “outliers”, dovuti a cause di vario tipo. Non è da escludere la presenza di errori umani nella fase di recupero del dato, ma anche il mal funzionamento di sensori che porta alla mancanza di pacchetti di dati o, più semplicemente, rumori di fondo dovuti ad interferenze. Fondamentale è quindi valutare l’integrità e bontà del dato nel tempo, garantendone la corretta estrazione e il minor errore di misura possibile in base al segnale da noi campionato. Un dato sporco può comunque essere trattato a posteriori e si possono ricostruire via software intervalli mancanti.
La terza fase consiste nella modellazione e analisi dei dati raccolti . I dati immagazzinati e puliti, infatti, devono portare ad un’analisi di causazione o, in ogni caso, implementare dei modelli di previsione sull’andamento dello sviluppo del prodotto. Lo studio delle variabili in ingresso deve, in altre parole, portare ad una previsione delle variabili in uscita, in modo da essere elaborate con un modello a supporto delle decisioni, che possono essere prese in tempo reale dalla macchina, autonomamente o sotto la supervisione di un operatore, allo scopo di risolvere problemi ed ottimizzare i tempi di lavorazione. Si può, però, permettere un’autonomia gestionale anche a sistemi che lavorano su livelli logici superiori, portandoli a prendere scelte a livello di filiera. L’incertezza dovuta ai parametri di studio e gli errori di misurazione, devono essere sempre presi in considerazione, poiché influenzerebbero i dati statistici su cui lavorano i modelli decisionali. Bisogna attivare una serie di statistical process control volti a cogliere la stabilità del processo nel tempo e la previsione della normalità. L’analisi punta a scoprire le cause su cui poter lavorare per influenzare gli effetti. Ancora una volta dobbiamo quindi ragionare in termini di variabili, dove delle variabili di dominio possono essere influenzate a nostro vantaggio e portare alla variazione delle variabili di codominio.
Nella quarta ed ultima fase , dopo aver compreso su quali variabili andare ad agire e quali controllare, si può definire un sistema di decisioni e azioni coerenti che permettono un supporto continuo contro le sfide che si ritrovano in termini di produttività, di qualità, efficienza, processo e manutenzione. Si devono, quindi, definire una serie di keep performance indicators che siano coerenti ai parametri definiti in precedenza e degli obbiettivi in base al portafoglio prodotti. Studiate le variabili possiamo, dunque, andare a definire un modello di miglioramento o un relativo piano d’azione, prendendo sempre in considerazione parametri d’incertezza. Si è allora pronti a muoversi in una logica non più reattiva, bensì con una mentalità proattiva che deve tenere conto del sistema dinamico di supporto alle decisioni. Dalla fase di analisi viene, infatti, realizzato un modello in base al volere dell’azienda, che potrà seguire un sistema lineare o non lineare. Fornire supporto alle decisioni consiste, per noi, nella implementazione di un sistema decisionale che ottimizza modelli. Il nostro obbiettivo è, per esempio, quello di portare a target nominale variabili dimensionali, oppure minimizzare variabili come le non conformità o massimizzare livelli di saturazione degli impianti, per raggiungere la migliore efficienza. La r obust production garantisce un sistema produttivo robusto che sia in grado di superare ogni causa di variabilità dell’uomo, della materia prima e della macchina. Il discorso si rispecchia facilmente dal lato prodotto, dove si possono prevedere variabili durante lo sviluppo, permettendo il raggiungimento del mercato senza alcun imprevisto con il cosiddetto robust design .